Hadoop has its own set of constraints and problems, and when you throw BI into the mix it's a whole other ballgame. As companies move their EDW to Hadoop, they expect to be able to migrate their analytical applications as well. While workloads such as ETL, predictive analytics and machine learning work great on Hadoop, the more performance-sensitive BI applications suffer from Hadoop's inherent low latency.
We’ll discuss these five harbingers of Hadoop doom and gloom and look at what can you do to avoid those pitfalls and be successful when setting up your own BI on Hadoop endeavor. To begin with, good planning, as is often the case, is an excellent starting point. You need to ensure that you have buy-in from management, and your internal domain experts are actively involved. Your computer hardware and network also need to be able to handle big data otherwise your system might be painfully slow or unreliable. Finally, in order to make efficient use of your big data you will need Business Intelligence (BI) capabilities, SQL and the ability to run complex queries.
1 - Good Planning
The first factor that can result in the failure of your BI on Hadoop project is a lack of good planning, in terms of project scope, budget, time frame, hardware (server storage, and computing power), and network requirements. Another reason is a lack of buy-in from top management. Make sure management appreciates the value of your big data project, and your Business Intelligence (BI) framework, and integrates it into their decision-making process. Historically-isolated data silos in your organization also pose a barrier and need to be taken into account during planning. “60% of big data projects will fail to make it into production either due to an inability to demonstrate value or because they cannot evolve into existing EIM processes,” concluded Roxane Edjlali, Chief Data Officer Research and Advisory at Gartner.
Understanding Hadoop Project Costs
Project costs are often underestimated, or not fully understood, resulting in poor scope and planning. A useful reference when calculating the cost of big data projects is the Forbes article ‘The Big Cost Of Big Data’. According to the authors, a petabyte Hadoop big-data project can cost around USD 1 million, including up to 250 nodes, compared to tens or even hundreds of millions of US Dollars for an enterprise data warehouse project.
Hardware
Begin with small, iterative steps, and let your organization’s internal domain and data experts experiment with Hadoop using a flexible, and open data infrastructure. Select server hardware, and network infrastructure that is up to the task. Pay attention to your Java Virtual Machine (JVM) and garbage collector, memory settings, and the Input/Output (disk and network input and output) speeds of your server hardware. Also consider investing in NameNode High Availability (HA, and secondary NameNode), and Disaster Recovery (DR) hardware.
Appropriate Use Cases
Even if the costs are well understood, the use-case may be incorrect. This can mislead you into building a solution that meets all the requirements of the plan, but does not fix the problem you intended to solve in the first place. To prevent this, focus on the goals, and document a number of detailed use cases that will help you configure your system to them.
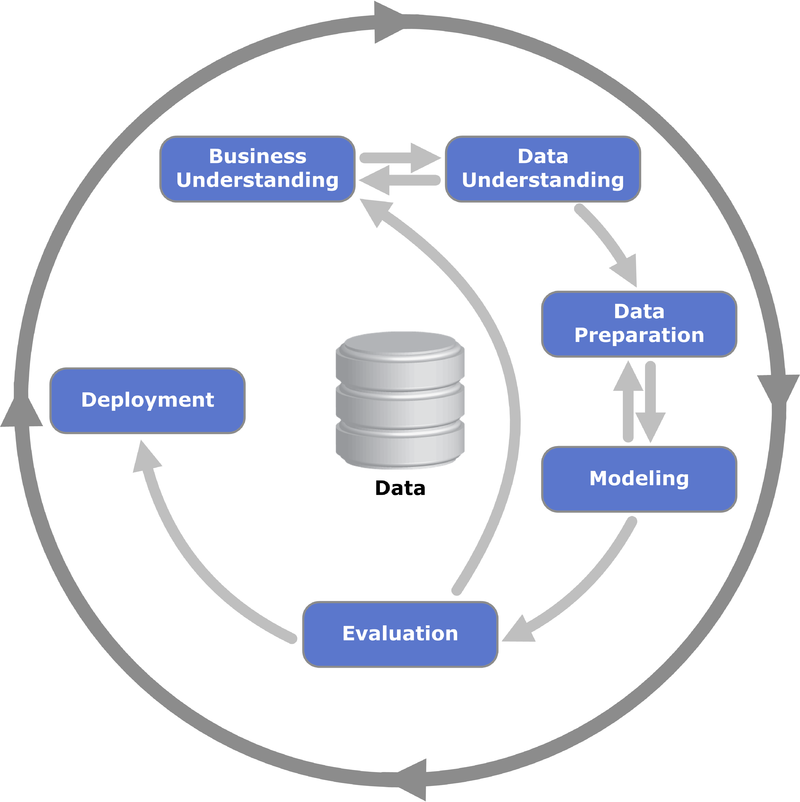
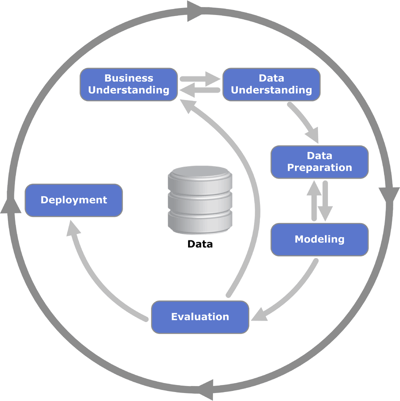 Figure 1. This diagram shows the relationship between the different CRISP-DM phases in a data mining project. (Kenneth Jensen via Wikimedia Commons)
Figure 1. This diagram shows the relationship between the different CRISP-DM phases in a data mining project. (Kenneth Jensen via Wikimedia Commons)
Your EIM Model and Knowledge Silos
Over-reliance on only data experts, without the active involvement of your organization’s own domain knowledge experts, is also cited as a common reason for failure. You may end up building an impressive project, but it also needs to fit into your organization's EIM model from the organizational vision and strategy, to the existing data infrastructure. You will need to adjust existing business models, and the business culture in your organization to enable improved internal data sharing and utilization.
The CRISP-DM (Cross Industry Standard Process for Data Mining) process model is a useful standard for BI and covers the full process from understanding the business and data, to creating a technical solution that can provide new insights and improve your business.
2 - Performance and Stability
Another important factor that can lead to the failure of a big data project is the stability and performance of the system. Ready access to data, and the ability to process it within acceptable latency times is critical. Performance and stability depend partially on the selection of appropriate hardware and network infrastructure, but also on the architecture of the SQL-on-Hadoop solution. The tools and the architecture must be suitable to your specific use cases and your BI dashboard requirements.
Get Help from a Big Data Vendor
It is advisable to work with a reputable and experienced big data vendor since building a distributed computing big data project is complex. The vendor can provide support, training, and certification for Hadoop, SQL-on-Hadoop solutions, and BI tools. Companies such as Cloudera, Pivotal, and Hortonworks, can help you setup a Hadoop virtual machine, for example, so that you can begin exploring the options for your big data solution.
Hadoop Performance
Hadoop does not guarantee standard response times and is optimized for dealing with large batches of files. As such, an out-of-box Hadoop installation may not be relevant for interactive queries on your data. Hadoop is designed around Java and JVM technologies, and as such can suffer from performance problems, such as the 'Stop of World' garbage collector issues.
3 - Business Intelligence on Hadoop
The third factor on which the success of a Hadoop big data project depends is its ability provide useful, near real-time BI. In the majority of new big data projects, this is not the case.
An Additional Software Layer
To build a fast, and usable BI dashboard, that can let you access the information you need, when you need it, with near real-time latency, you will need an additional software layer that can query your data. Be careful with generic out-of-the-box BI solutions - they are often slow, may not be suitable for your a specific use case, or just not flexible enough to adjust to the specific needs of an organization.
A Query Acceleration Engine
Organizations use various SQL-on-Hadoop solutions, such as Hive, and Apache Impala, to enable SQL queries on Hadoop, but often learn that they are not fast enough, or flexible enough for unique resource-hungry needs of BI. Another alternative would be to add a BI solution that integrates with Hadoop, and in addition, consider using an acceleration server that sits on top of Hadoop.
An example of one such solution is that provided by Jethro. This solution has an efficient indexing architecture that allows data updates to be loaded incrementally, without locking the indexes. The solution uses intelligent caching and automatic micro-cubes, compresses and sorts data, and creates multi-hierarchical indexes for every column of a large dataset.
Jethro can process, index, and compress a Hadoop system by up to a factor of ten. This not only saves on storage but also reduces the load on data storage hardware, and results in much faster and more efficient operation of the operational infrastructure.
Data Ingestion
For useful BI you also need to ensure efficient ingestion of new data into your database. When you set up your BI solution, check that it can meet the minimal required latency times for data ingestion. If not configured well, data ingestion can cause extensive system downtime, and result in users missing current data updates in their queries.
4 - SQL on Hadoop
Even though SQL is the default query language used by data analysts (over 30% use it according to KDNuggest Poll), unfortunately Hadoop does not support SQL out-of-the box. SQL enables connectivity with BI solutions, but an additional software layer such as Apache Hive, and an acceleration engine, are needed to ensure acceptable BI performance. Some organizations start of using SQL technologies but soon come to the conclusion that SQL-on-Hadoop solutions alone are not enough to meet their specific requirements or use cases.
SQL-on-Hadoop Solutions
SQL-on-Hadoop solutions that are used for querying big data include Data Warehouse (DWH) solutions such as Cloudera's Impala – an open-source Massively Parallel Processing (MPP) query engine, or Pivotal's HAWQ big data analytics solution. The Impala engine provides an SQL-like interface, but uses batch processing partitions instead of indexes, and does not provide multi-tenancy. Apache Hive also provides an SQL-like interface for queries on a Hadoop database, but may require the addition of an acceleration engine.
To see a more detailed breakdown of the SQL-on-Hadoop solutions, view: Hadoop Hive & 11 other SQL-on-Hadoop Alternatives
5 - Fast Query Response Times
In order to successfully execute a big data project it is important to understand that Hadoop is a two-tier solution, which consists of a Distributed File System (HDFS) and the Resource Allocation and Task Management (YARN) resource manager. In fact, Hadoop is not a database, but ‘an open-source software framework for distributed storage and distributed processing of very large data sets on computer clusters built from commodity hardware’ (source: Wikipedia). Hadoop was in fact designed to store and process huge amounts of structured, semi-structured and unstructured data on commodity hardware. Additional requirements such as SQL support, interactive response times, indexing and caching data were not the main focus of Hadoop designers.
Query Response Times
To run queries on Hadoop partitions you will need to design a query-based solution, preferably one that uses indexes, otherwise the solution will need to scan the entire database, or all the data in a partition each time, resulting in poor performance, and unacceptable latency. Indexing is especially important for use cases where users need to perform selective queries, and retrieve small subsets of data for further analysis. On top of that, an acceleration engine can improve query response times even further, from a maximum of hours for complex queries to several minutes, or seconds for simpler queries.
Advanced Queries for BI Dashboards
A good BI dashboard can provide advanced querying capabilities including standard off-the-shelf reports, charts and widgets, or can enable users to drill down and extract information using their own specific queries. Additional querying options may include ad-hoc reports using many different filters such as region, time, or specific URL, and cross-tab reporting for comprehensive correlation analysis. An efficient query engine that uses indexes, will result in a much faster interactive dashboard experience, with minimal load on the Hadoop cluster hardware and network infrastructure. Advanced querying engines can even can use more than one index at once, auto-cubes, and columnar indexing improving performance even further.
To Summarize
In order to set up and run an effective big-data Hadoop project that provides reliable BI, your organization will need to adopt a new mindset that addresses not only the technology, but also the organizational EIM. You will need to conduct a comprehensive analysis of your business with the help of analysts, internal domain experts, and strategists to come up with robust and relevant business use cases. You will also need buy-in from management, and take company politics into consideration.
Your big data project needs to work with your existing BI tools, and your security and monitoring systems. Data security needs to be addressed because standard Hadoop implementations have relatively poor security, and many organizations are wary of keeping all their data in one location.

