Last week, Cloudera published a benchmark on its blog comparing Impala's performance to some of of its alternatives - specifically Impala 1.3.0, Hive 0.13 on Tez, Shark 0.9.2 and Presto 0.6.0. While it faced some criticism on the atypical hardware sizing, modifying the original SQLs and avoiding fact-to-fact joins, it still provides a valuable data point:
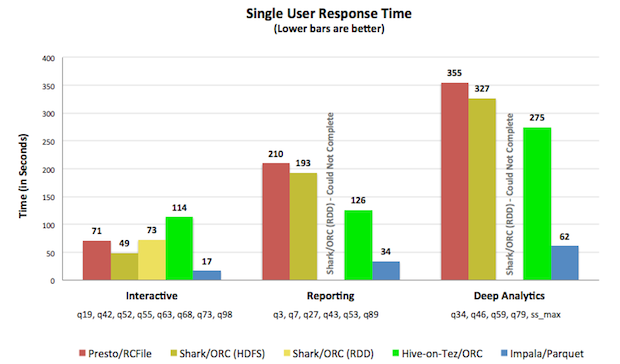
We at JethroData thought it would be interesting to take Cloudera's benchmark as is, run it and get a feeling on how do we compare. Now, TPCDS benchmark is not the best way to highlight JethroData's strength - our automatic indexing shines the more you add predicates, the more selective the query is. But still, it is another data point.
How did we test?
Hardware - we didn't have 21 very powerful physical servers laying around... Instead we provisioned two small clusters on AWS, with the following configuration. For the NameNode we picked m3.xlarge (4 cores / 15GB RAM / 80GB local SSD). For the DataNodes we picked m1.xlarge (4 cores / 15GB RAM / 1680GB local disk) - 3 nodes for JethroData, 5 nodes for Impala. We picked this instance type as it provides the required disk space. For the JethroData Node, we picked an additional single r3.2xlarge (8 cores / 61GB RAM / 160GB local SSD) where we process our query.
Both clusters had the same hourly costs - JethroData had its query node, and Impala got two extra data nodes for the same price (both costing 70 cents per hour).
Data and Queries - we used Cloudera's Interactive queries from their test suite. We used scale factor 1000 (1TB) for this test (3 billion rows in the store_sales table). We had to do one minor modification to a couple of queries - since our SQL dialect does not include CASE expression yet (it's in our backlog), we replaced the CASE expressions with IF functions - IF(condition, value_when_true, value_elsewhere).
With this Hadoop cluster sizing, there was not enough memory to keep all the test data in memory, making the results more realistic.
Results
Here are the initial results we got:
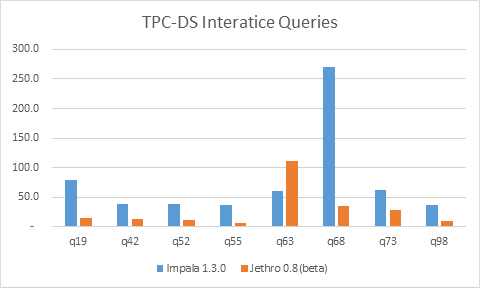
Query 63 has uncovered a performance bug in our WHERE processing that will be fixed in the coming weeks. Excluding that query, we were on average 5x faster then Impala.
What's Next
While these initial results are already good, we think there are other things we want to highlight:
- We plan to repeat the benchmark on a larger data set and a larger Hadoop cluster. We will also share the Hadoop cluster utilization numbers to show the impact on the cluster.
- Test on a busy cluster - all the tests were running on an idle Hadoop cluster. Those idle clusters are not that common, especially with the trend of putting many different workloads on a shared cluster.
- Our experience is that adding additional background workload to the Hadoop cluster (like MapReduce jobs) effects the performance of Impala much more than JethroData's, as JethroData just accesses HDFS and does not run processing on the Hadoop cluster.
- Try more selective queries - TPCDS does not specifically highlight our strength - leveraging indexes for drill downs. Our tests show that as you add more predicates to a query, our performance significantly improves as we need to fetch and process less data, while Impala's performance is less affected (as it stills needs to scan the same amount of data).

