Say you’re an analyst using Tableau with live-connect to Hadoop to visualize and analyze your glorious big data—somewhere in the neighborhood of 2,879,987,999 rows. A few clicks and drags later and you’re glued to your desk staring at the loading spinner of doom and gloom wondering if your dashboard will refresh before your jeans go out of style.
Now, you might be thinking to yourself, “Whoah, I can live-connect Tableau directly to Hadoop? Cool!” The answer is yes, you can. Or maybe you’re a more advanced user and think, “We already use Hive/Impala/SparkSQL to access our Hadoop data, but it’s far from an interactive experience. Sometimes it works, more often it’s slower than a snail on peanut butter.”
When you want your BI tool (Tableau, Qlik, Microstrategy etc.) or your own analytics dashboard to access data on Hadoop you’re going to need to add a SQL-on-Hadoop layer. Hive, Impala, Presto and SparkSQL all classic examples of SQL-on-Hadoop’s. If you take a look under the hood, you’ll learn that these are designed as MPP (Massively Parallel Processing) architecture that typically requires a full-scan of the dataset rows for every query. This works well with certain use cases like with predicative analytics or machine learning jobs. However, full-scan based solutions by nature will not deliver consistently interactive-speed BI—even if your company has already poured tons of coin and effort trying to make a square peg fit into a circular hole. We’ve seen many tech teams with the best intentions pave this perfectly executed road to BI-on-Hadoop project failure.
So, if you want to melt your frozen data lakes and unleash truly interactive BI on Hadoop—at any scale and without sacrificing any data freshness—you’re going to need to get a SQL-on-Hadoop engine that was designed for the specific use case of BI-on-Hadoop. Sounds logical enough, right? That's exactly why we created Jethro 2.0.
Jethro 2.0 was carefully crafted to deliver a consistently interactive BI-on-Hadoop experience in almost any scenario. In order to do this tricky feat, the team at Jethro went to the drawing board and architected a product that combines a columnar SQL engine with search indexing. Instead of scanning all the rows with every query, Jethro uses indexing, micro-cubes and query-result cache to deliver queries from Hadoop back to a BI dashboard at interactive speed. Jethro was designed to run as an edge node and all its data never leaves HDFS.
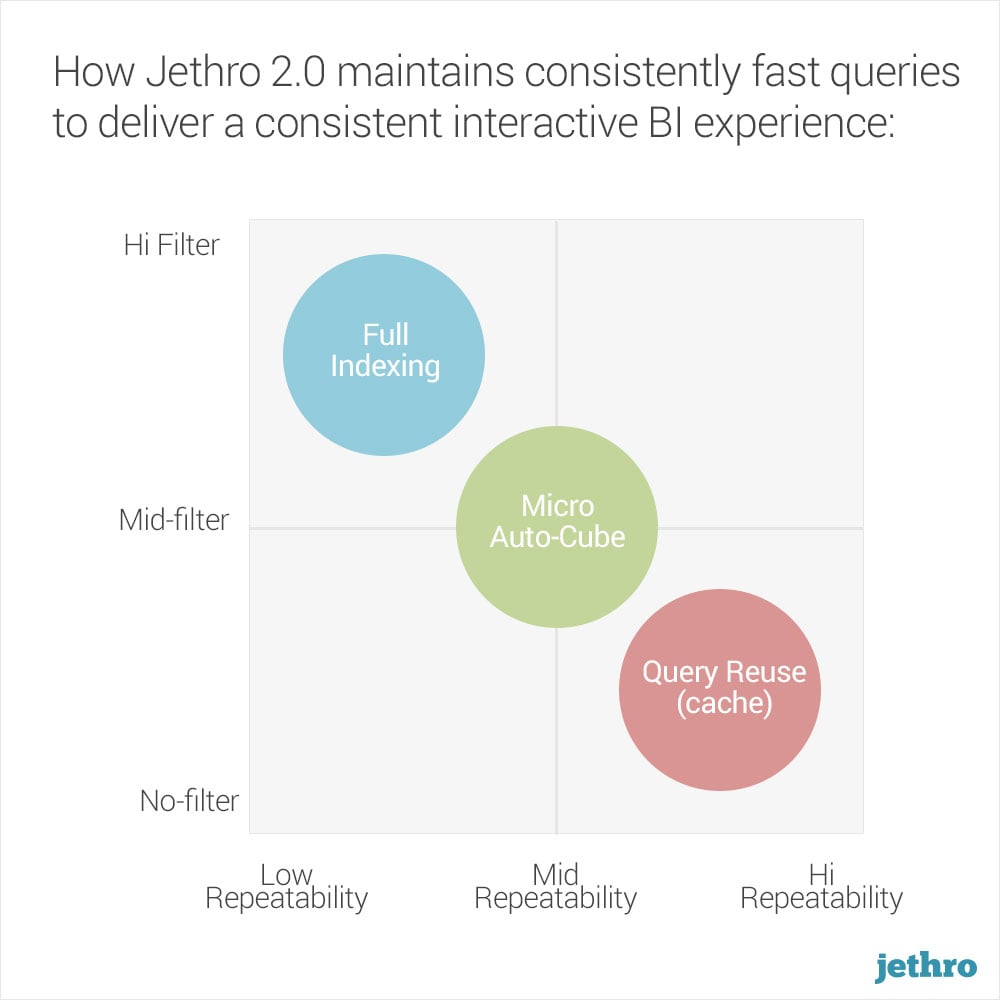
- Indexes are utilized when queries are filtered. It allows Jethro to surgically access only the data needed for the query and stream results to the BI dashboard
- NEW to Jethro 2.0 are “auto micro-cubes” which further accelerates performance. These are small aggregations (similar to OLAP cubes) that are dynamically generated by Jethro based on actual query patterns that Jethro learns. Large cubes are avoided by using indexes to speed up queries with multiple filters or high cardinality columns
- Query-result cache is managed by Jethro which captures the results of each query and decides to store it in HDFS based on result-set size and total execution length. When the same query repeats, as is typical for dashboards, it will be served out of cache with no processing
Jethro’s three performance features work in tandem and complement each other in delivering consistent interactive BI experience in almost any scenario the fastest query response time. The cubes are complementary to Jethro’s indexing and caching. ensure that Jethro can consistently accelerate the query performance of BI tools and dashboards in almost any scenario.
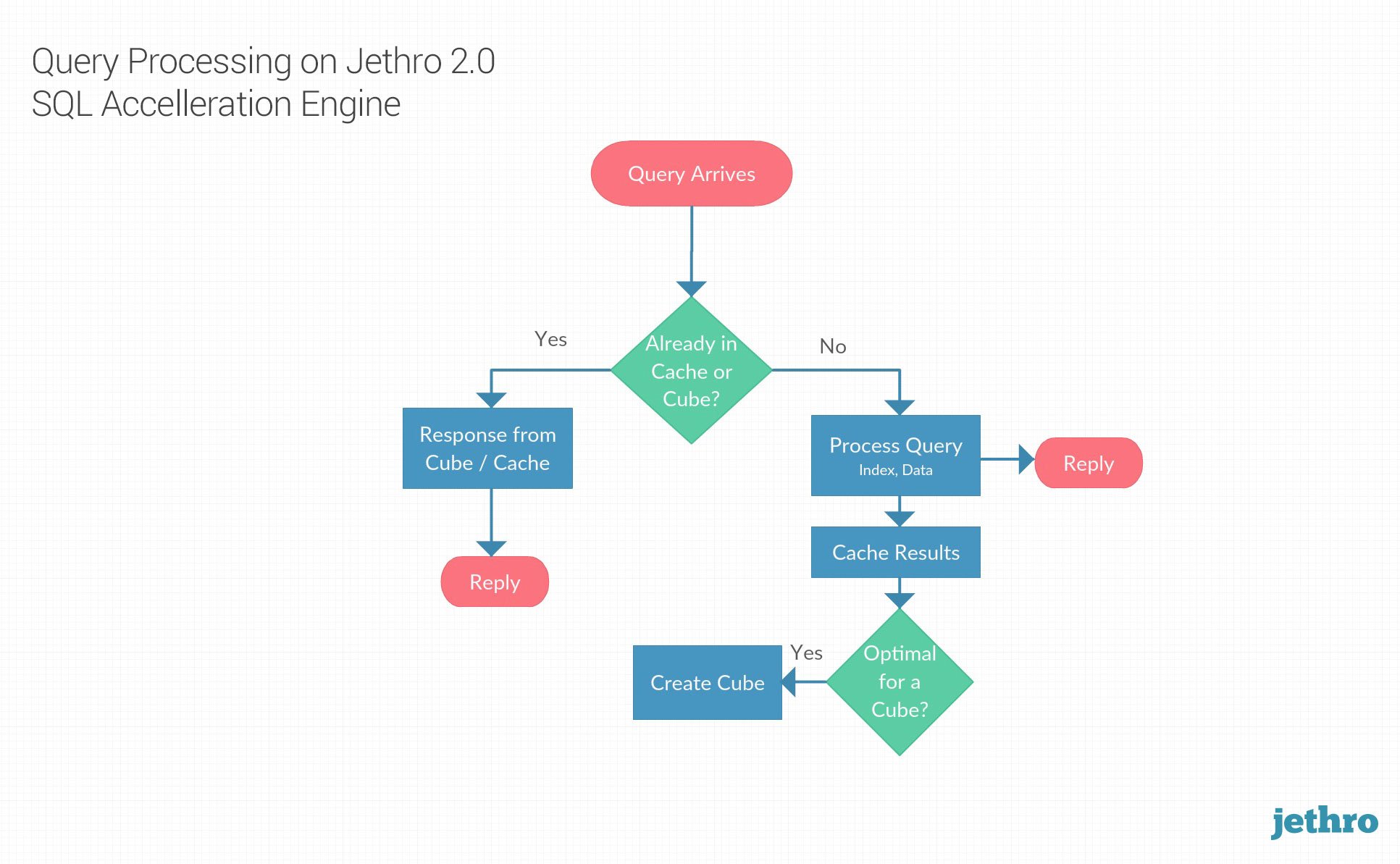
When a BI tool sends a query to Hadoop, Jethro’s three performance features work in tandem to deliver the fastest query response time. The Jethro SQL Acceleration Engine categorizes the query and delegates it to the optimal process.
Whether the end user is an analyst visualizing 2,879,987,999 rows of data on Tableau, or even a the client or a large company with a SaaS BI/ analytics dashboard looking at his own metrics, Jethro 2.0 is a must-have addition to the tech stack for a consistent interactive-speed business intelligence experience.
Access a live demo to see how your blazingly fast your BI tools and analytics dashboards can be.

