Jethro Manager adds a Web UI to the Jethro Engine
Jethro manager is part of Jethro 3.0.
Jethro is proud to release a new Web UI that will allow its users to manage and perform actions on their Jethro servers using a remote web browser.
The first version of the product focuses on features that are most commonly used, activities that are most time consuming, and tasks can benefit users the most through the help of a visual guiding mechanism:
- Create & attach Instances
- Load from CSV data files located on a Local/Network/Hadoop file system
- Load directly from Hive files of any format
- Monitor load statuses and logs in real-time
Having a Web UI not only reduces the need to use command lines on Linux machines, but also takes advantage of the new interface to prevent users from repeating commonly known mistakes. The UI guides users with on-screen tips and rules that will better optimize their Jethro Server performance.
Let’s see a few screenshots from each feature, to better understand how it’s done.
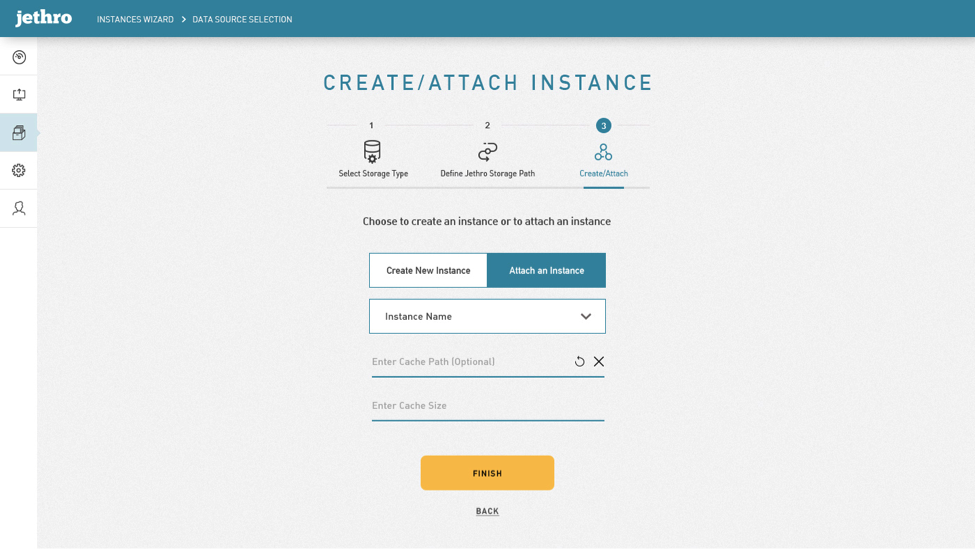
Create & attach Instances
The ability to create and attach instances in Jethro Manager (JM) is designed through a wizard with three simple screens. The first one identifies the type of storage platform. The second navigates to the location where the Jethro Instance files will be stored within that storage. The third one asks for the name of the instance and the location and size of its local cache storage.
If an unattached instance is already found on the storage path provided, JM will offer the user the ability to simply select it from a dropdown list.
Upload data from files
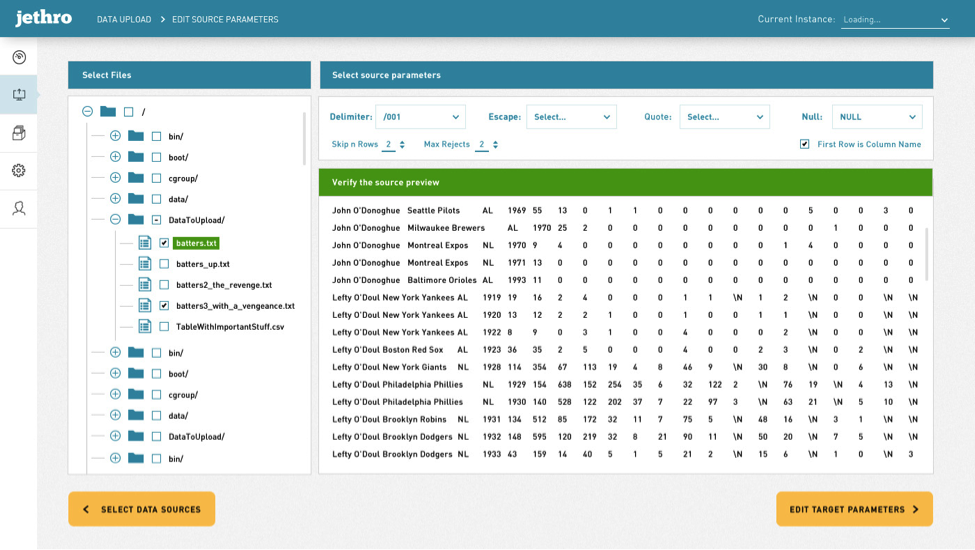
The data upload flow consists of three screens. First a user chooses the type of data source. Then a user can navigate through folders, and select the files (or folders of files) to be loaded. On the third screen a user can map the source data to the target tables in Jethro, and to initiate a load process.
Users who are already familiar with Jethro will be glad to hear that no more description files editing is required.
Going back to the second screen—once the file(s) have been chosen by the user, JM will try to identify its delimiter char automatically and preview the data of the file in colors together with other parameters that can be selected and affect the way the file will be processed during the load.
On the third screen the user will be asked to verify the mapping of columns from the source file(s) chosen on the previous screen, to a target table in Jethro. It can be a new table, or an existing one.
When creating a new table, JM will try to suggest the data types it sees as the best fit for the source data, while considering Jethro’s optimal preferences. The user will still be able to change the recommendations according to his own preferences.
When choosing an existing table to load the source data into, JM will try to identify the best existing table based on the data types identified on both sided of the map and will generate a match percentage score, which will appear next to each table name on the list. This score helps users with hundreds of tables in identifying their required target table and prevent mistakes such as loading of data into a wrong table.
JM also provides indications for the match quality between the linked source and target columns—if it thinks the mapping is wrong or could be better optimized. If a mapping between two columns doesn’t match, JM will notify the user via color, icons and tooltips.
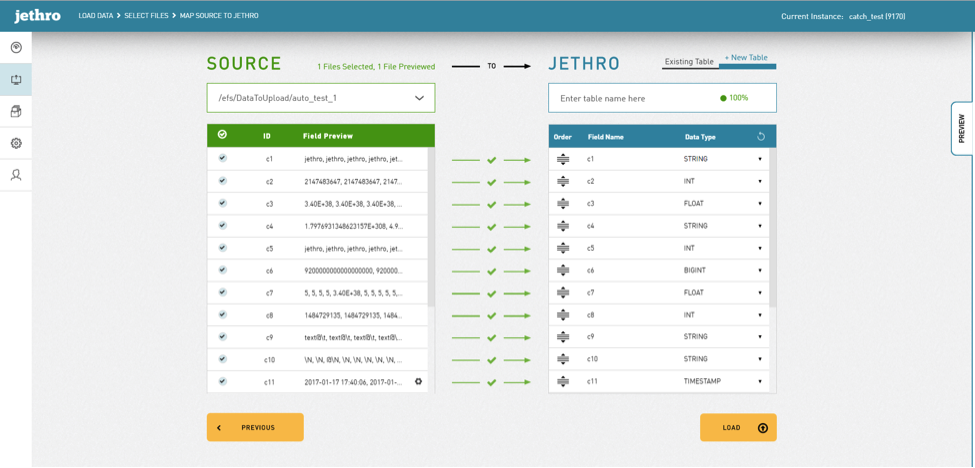
The user will also have an option to select specific columns on both the target and the source, and to get a preview of their data right next to each other. Again – this comes to prevent commonly seen mistakes.
Loading data directly from Hive or Impala
The process of loading from Hive or Impala is practically the same as of the loading of files we’ve seen previously. The only difference is that you will query your Hive/impala metastore for table list instead of the directory file tree.
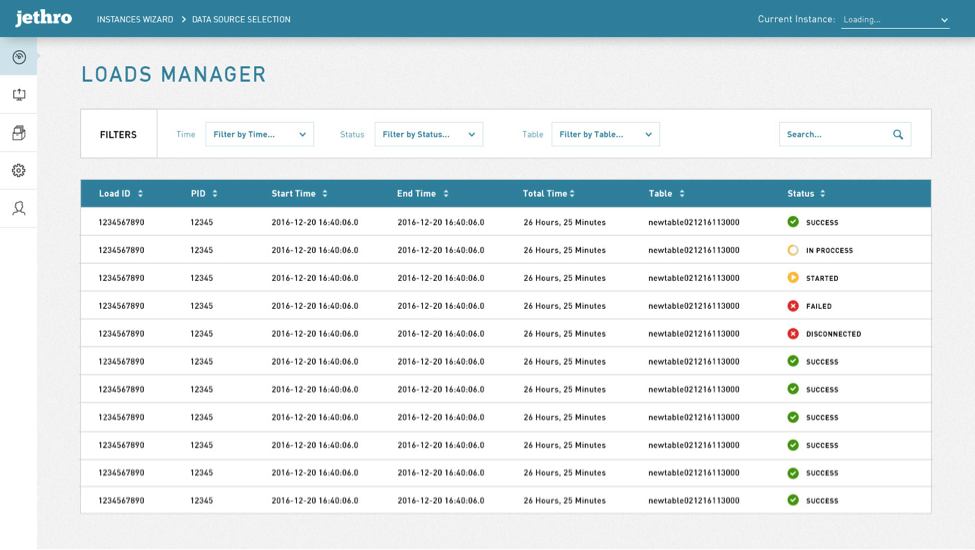
Monitoring load statuses and logs in real-time
The load manager screen will allow the users monitor the progress of load processes, and in case anything goes wrong, be able to access the logs.
JM offers the ability to repeat a load process within a single click. If a load process has failed due to a simple mistake that can be fixed, the user will be able to jump back to the historical load flow definition, and change whatever is required to make the load process succeed.