Many Tableau users are connecting Tableau to Apache Hive, in order to visualize big data stored in a Hadoop cluster. In this short post we’ll review how to connect Tableau to Hive, some performance issues you might experience on Tableau with big data, and a proposed solution.
Connecting Tableau to Hive
For Tableau, Hadoop with Hive is just another data source. There are two strategies for importing Hive data into Tableau:
- A Live Connection, which pulls the entire set of data into Tableau and updates it on an ongoing basis
- Extracts, in which you select a subset of your data lake and pull it into Tableau
See the Tableau Knowledge Base for detailed instructions on connecting Hive data to Tableau.
Hive on Tableau - Slow and Steady...
If you are working with Hive on Hadoop (the original Hive based on Map/Reduce), queries will run relatively slowly because Hive is built for scale, not performance. In a data visualization platform like Tableau, it’s important to be able to work with the data interactively, slice and dice and switch between metrics and dimensions quickly.
Tableau recommends working with Extracts, not Live Connection when connecting Hive to Tableau, to avoid performance issues (see the Tableau white paper, “5 Best Practices for Tableau & Hadoop”).
Improving Hive Query Performance - For Smaller Data Sets or Predefined Queries
To address the performance issues, it’s possible to supplant Hive with a fast query engine, which will allow you to work interactively with your data on Tableau. There are several performance-optimized engines out there that can help deliver interactivity with Hive data on Tableau:
To see a complete roundup of SQL-on-Hadoop tools optimized for performance, see our post “Hadoop Hive and 11 SQL-on-Hadoop Alternatives”.
What’s common to all the tools above is that they are based on a Massively Parallel Processing (MPP) architecture, and their performance optimization is based primarily on in-memory processing and optimized storage formats. This means they can deliver interactivity on tableau in one of the following cases:
- Smaller data sets or extracted data - it’s common to extract a sample or subset of the full “data lake”, to enable the query engines to store the data in memory and be able to process it fast enough for interactive exploration of the data.
- Predefined queries - for example, if it is known in advance that users will query the data by date, it is possible to organize the data in an optimized columnar format, with each column representing a date. Then, when a user performs a date-based query, the query engine can read only the relevant columns pertaining to the required date range, instead of performing a full scan on the entire data.
For larger data sets in excess of 1 billion rows, or flexible queries that are not known in advance, especially when users “drill down” by applying multiple filters, the MPP approach is less suitable. Every filter the user applies requires an additional full scan of the data, and for larger data sets this means a long wait, even on a modern query engine.
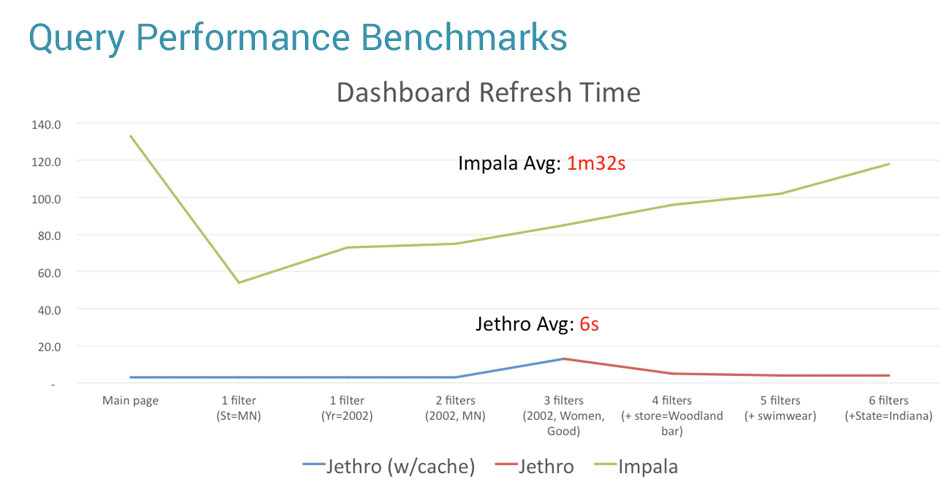
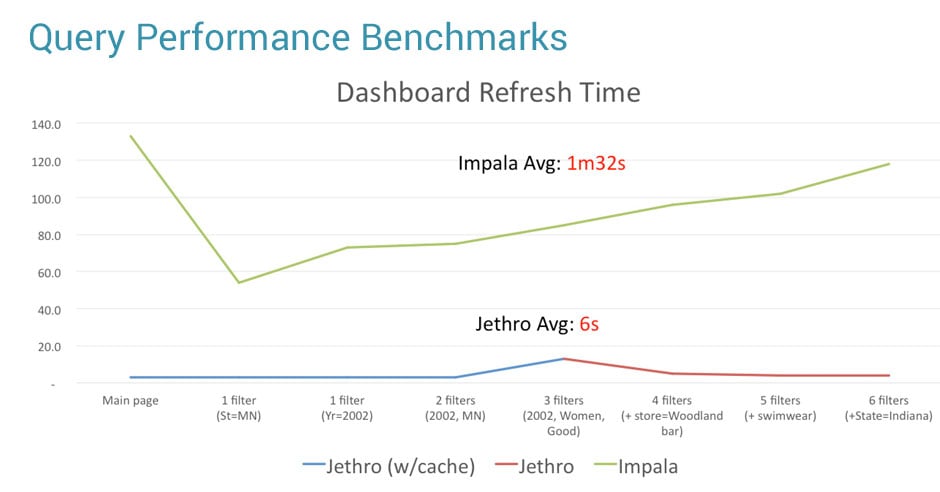
In a recent benchmark we carried out, which used a data file of 1TB, both Impala and Redshift took over 1.5 minutes on average to refresh the Tableau dashboard. This is much faster than traditional Hive with Map/Reduce, but still not fast enough to enable working interactively with your data.
Improving Hive Query Performance - For Larger Data Sets and Flexible Queries
An index-access architecture is the most flexible solution for directly querying your big data source directly from Tableau. As opposed to other engines that rely on MPP (massively parallel processing database) architectures that fully-scan the entire database with every query and drill-down, index-access architecture removes the need for limiting extracts or cubes and allows you to query your data and drill-down any way you’d like at interactive speed. Jethro is an index-access SQL acceleration engine that was built for the unique scenario of flexible user queries on large data sets. Instead of fully scanning the data (MPP) like all other SQL on Hadoop tools, it indexes every single column of the dataset on Hadoop HDFS.
Jethro leverages these indexes to surgically access only the data necessary for a query instead of waiting for a full scan, resulting in query response times that are faster by an order of magnitude. This enables a true interactive response to queries and speed-of-thought exploration of data on Tableau. Queries can leverage multiple indexes for better performance - the more a user drills down, the faster the query runs.
In the above benchmark, while Impala and RedShift took over 1.5 minutes to refresh the Tableau dashboard, Jethro took only 6 seconds on average. This enables truly interactive data exploration on Tableau, even for very large data sets and with constantly changing user queries.
Accelerating Tableau Performance
At Jethro our passion is accelerating Business Intelligence tools like Tableau to interactive speed while live connected to big data.
- Interactive BI dashboards at Big Data scale
- No manual data engineering
- Seamlessly integrates with existing BI applications and data lake
Let's chat about your Tableau on Big Data project and how we can accelerate performance to interactive speed.
[av_button label='Schedule Webex' link='page,4220' link_target='' size='x-large' position='left' icon_select='no' icon='ue800' font='entypo-fontello' color='theme-color' custom_bg='#444444' custom_font='#ffffff']

