New York — September 9, 2016 — Jethro, provider of an index-based SQL acceleration engine that makes Business Intelligence (BI) work on Hadoop, is slated to release Jethro 2.0 at the Strata + Hadoop World conference in New York on September 27, 2016.
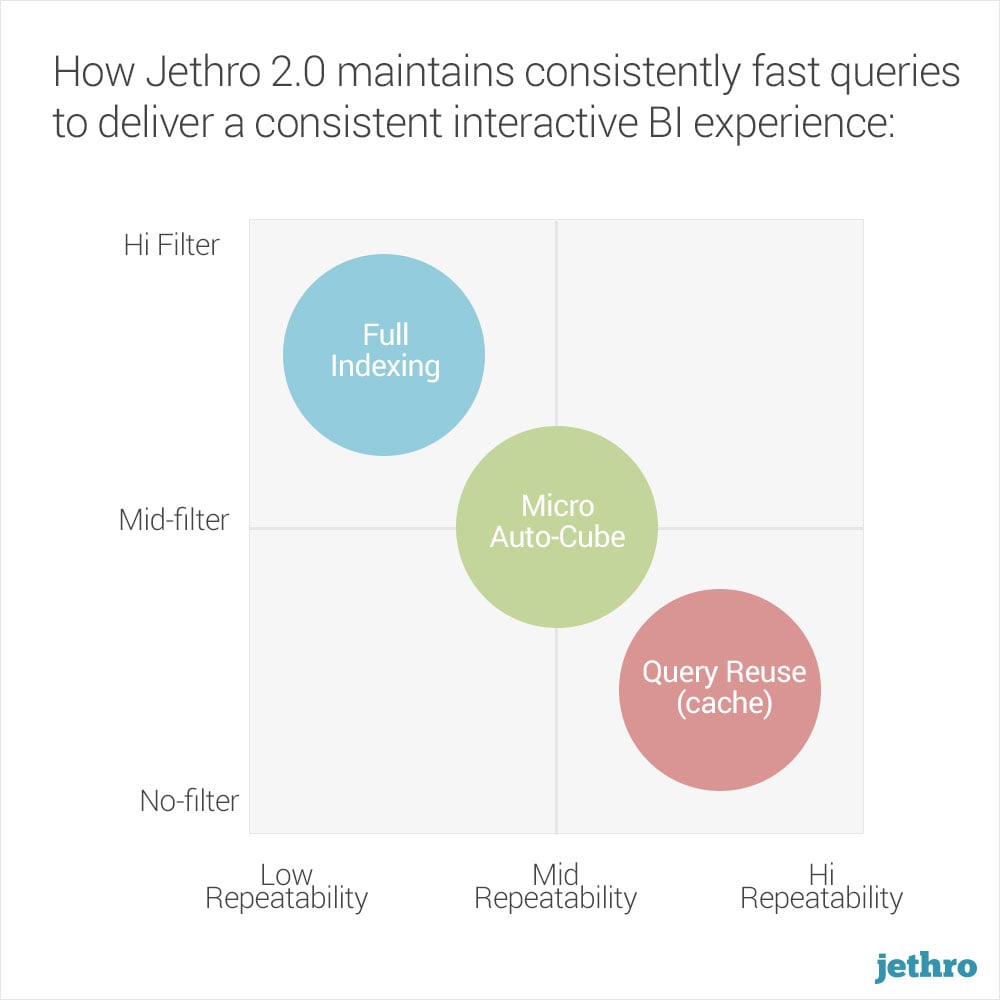
Jethro 2.0 features “auto-cubes,” which are dynamically aggregated micro-cubes that are automatically generated based on actual usage patterns that Jethro learns. The auto-cubes are complementary to Jethro’s full-indexing and intelligent caching, which significantly accelerate the query performance of BI tools and dashboards, consistently and in almost any scenario.
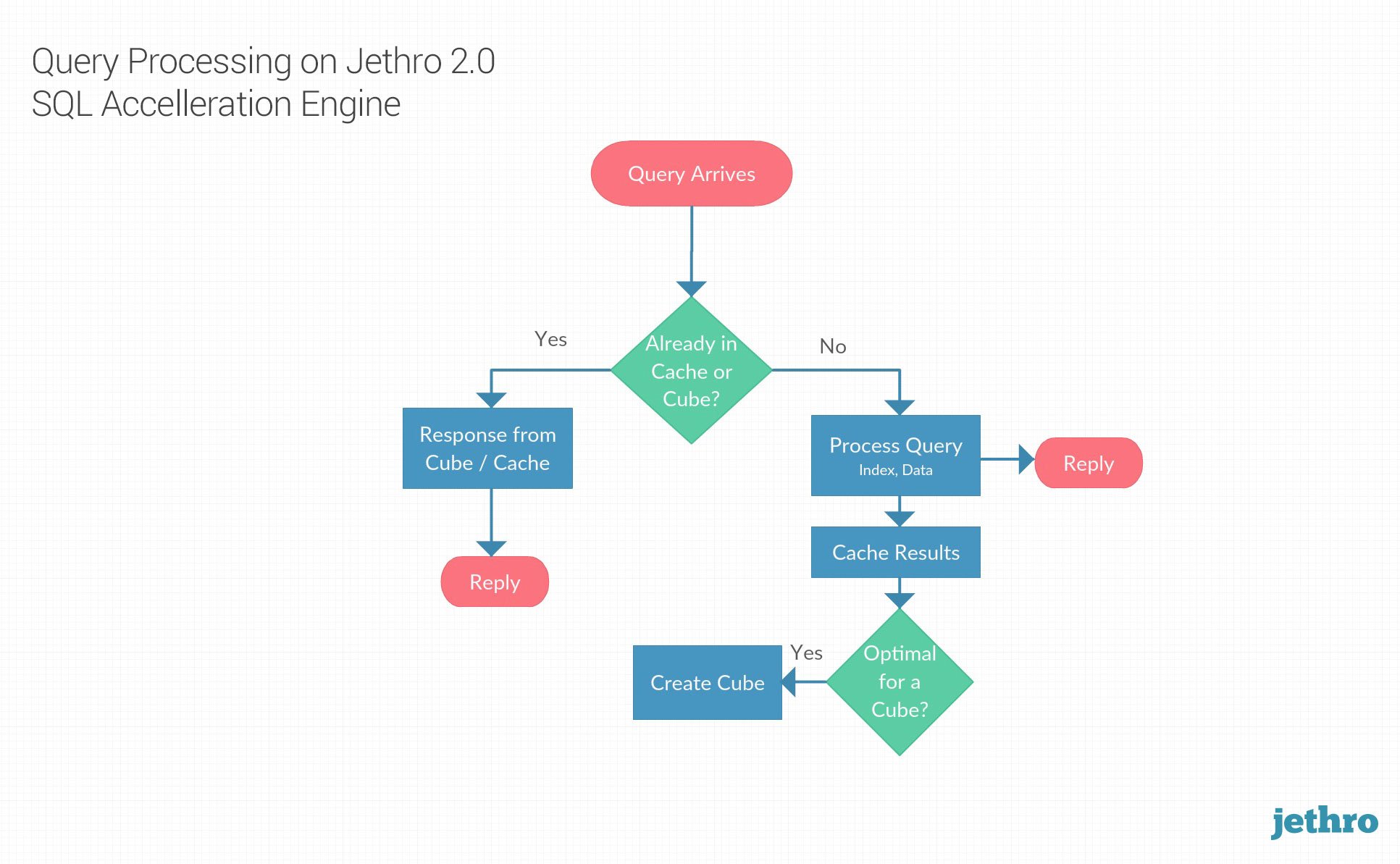
“The dynamic aggregation is a break-through feature in many aspects,” notes Jethro CTO Boaz Raufman. “Jethro’s dynamic aggregation comprises auto-cubes that are automatically generated based on user activity and are maintained and updated transparently. This technology delivers the great performance value of cubes and pre-aggregation without the cons of standard cubes. Jethro dynamic aggregations eliminate the need for complex cube design, provide unlimited coverage via hundreds of small cubes and allow transparent on-demand support for incremental data load. Dynamic aggregations are complimentary to Jethro indexes. The combination of those two powerful acceleration features enables Jethro to cover a extensive range of use cases and provide interactive response times to BI applications in almost any scenario."
In addition to the auto-cubes, Jethro 2.0 also includes increased support for Qlik View and Sense complete with set-analysis-like functionality now standard inside Jethro. The new version also features increased SQL coverage with more mathematical functions as well as complete JOIN.
The Jethro Acceleration Engine lets you keep your data in Hadoop and get the performance of an EDW engine. It is unobtrusively sandwiched between a BI tool and an existing data source. Jethro speeds up BI tool reporting and visualizations by 500%-5000%1 without putting any additional burden on the Hadoop cluster or other data source.
Jethro is a combination of two engines: columnar SQL database and search indexing. Think Impala plus Elastic Search, in one product. It looks and behaves like a SQL engine but leverages the full-indexing engine inside to power blazingly fast queries. It utilizes indexing, smart caching and micro-auto cubes to deliver a consistent interactive BI experience. Jethro seamlessly integrates with BI tools such as Tableau, or Qlik, as well as homegrown SaaS SQL BI dashboards. Jethro can connect to almost any storage system such as Hadoop, Amazon and other EFSs.
For press inquiries, contact Remy Rosenbaum: remy@jethro.io or +1 (917) 624-9911
1Demonstrated via independent TPC-DS live benchmark on 2.9 billion rows of data against competing SQL solutions.