Jethro Blog
SQL-on-Hadoop, BI-on-Hadoop, Big Data, Interactive Business Intelligence, SQL Query Acceleration and Everything in between.
What's new in JethroData 1.0
As we announced earlier today, JethroData 1.0 was just released. Since launching the public beta six months ago, we have added numerous improvements and bug fixes across the board. I would like to share some highlights:
Being "Creative" with TPC-DS Benchmark - Dynamic Partition Pruning
In this post, I would like to present a common optimization challenge, how it is solved in Jethro, and how some other SQL-on-Hadoop products "overcame" that challenge by manually modifying their benchmark scripts and queries to avoid the situation (which was quite a surprise for us when figured it...
Partitioning in Hive and Impala Versus Jethro
In my previous post, I explained how partitioning works in Jethro. In this post, I would like to explain how partitioning was implemented in Hive and Impala, why their design is very problematic, and how our implementation avoids those problems. Design matters!
Simple, Automatic Range Partitioning in JethroData
This post will introduce how the partitioning feature is implemented in Jethro. In a nutshell, we added a simple, automatic range partitioning mechanism that is very easy to work with.
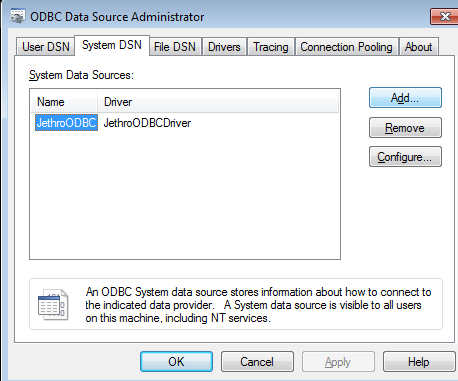
Connecting To Jethro from Tableau
Jethro allows fast interactive queries over big data, by indexing all your data. Tableau is a popular BI tool that can be used with Jethro. Tableau runs on Windows 64-bit servers and connects to databases using ODBC. In order to connect to Jethro from Tableau, all you need to do is install our ODBC...
Jethro and eBay’s Big Data Lab Project
In the end of 2013, Jethro was invited to participate in the first round of eBay Big Data Lab project. The project grant selected startups and researches access to anonymized data sets on eBay large internal clusters. We used the fantastic opportunity to...